A simple Naive Bayes algorithm that analyzes text and uses previous data to create a prediction of the sentiment of the text from 1 (strongly negative) to 5 (strongly positive).
Project code: https://github.com/marker6275/Text-Classifier
I took all the functions off AWS since AWS kept charging me for some reason (please fix). I had to delete my entire AWS account so the functionality doesn't work anymore. The page still exists but nothing will happen if you try to upload a file. It might still let you upload files, but they don't go anywhere since the S3 bucket and lambda functions were deleted.
**Does not work anymore**Initially, it was run on a Python file that prompts the user for their action and performs the inputted action.
Very basic.
But I adapted the Python code into React JS to be able to upload .txt files into AWS. Then, it can display the result of the analysis. There is also a line that shows the number of files currently in S3 and an option to clear those.
The project uses a serverless design with functions deployed in AWS Lambda. These functions are then callable from the client using a REST API.
I've adapted all the functions more or less into Javascript from the original Python client. There wasn't too much to do since it was mostly making and handling API calls and responses. The only problem I seemed to run into was the time it would take to fully evaluate functions so there's lots of downtime on this, but overall it seems to work.
One issue that appears on occasion is when the call to the server fails with status 502, meaning there was an error in the evaluation or calling of the API. There are general solutions to it such as try-catch handling or running the call until it responds properly. I currently have neither of those implemented and when it errors with 502, it will simply log in the console and nothing will happen so you might just need to run it again for it to work.
The naivebayes function will be triggered when a file is placed into the S3 bucket into the /files folder. When this happens, the function will then train the classifier on prewritten data from training_data/trainingdata.txt. The reason the model trains on every call to the function is because the model also appends the currently inputted text into the training data for (ideally) more accuracy. Currently the training data is just made up of text and ratings made from ChatGPT and random movie reviews, so the analysis isn't perfect.
Using the trained data, the classifier will then analyze the text from the passed in file and run a custom, simplier Naive Bayes Algorithm to determine the sentiment of this text. The algorithm also uses Laplace Smoothing and removal of stop words for more accurate analysis.
When the model finishes classifying the text, it will write the file's sentiment (a value from 1 to 5) into the output.txt file that is then uploaded into the output/ folder in the S3 bucket.
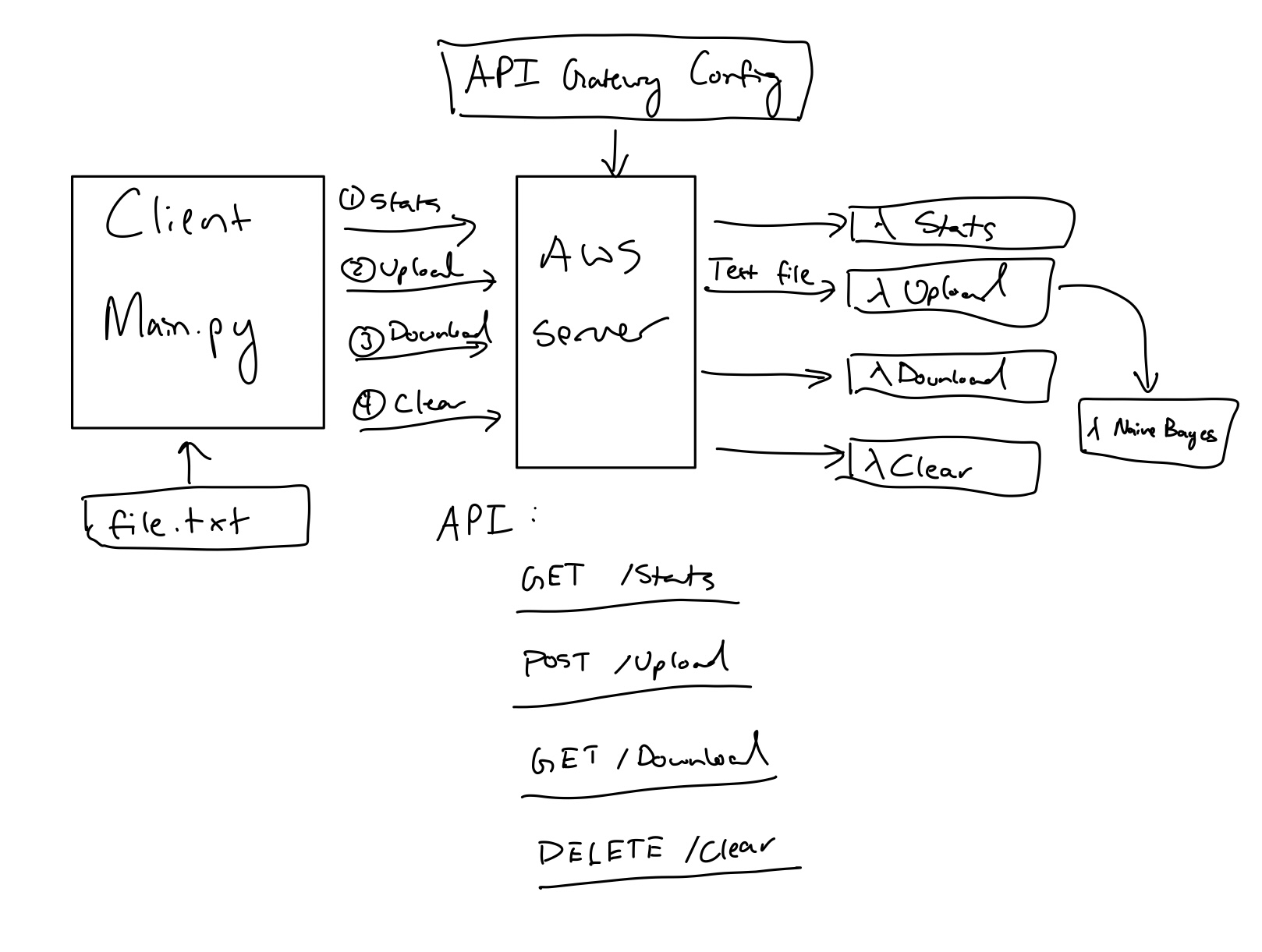
There are 4 API functions that the (original) client calls. All four of these are implemented here.